El equipo de Qwen ha anunciado Qwen3-Omni, su nuevo modelo fundacional diseñado para trabajar de forma nativa con diferentes modalidades: texto, imágenes, audio y vídeo. El modelo es capaz de generar respuestas en tiempo real, tanto en texto como en voz, y se ha optimizado para mejorar su rendimiento y eficiencia en comparación con versiones anteriores.
Principales características
Entre sus novedades, Qwen3-Omni ofrece soporte multilingüe, con interacción en texto en 119 idiomas, comprensión de voz en 19 y generación de voz en 10. Además, permite entender audio de hasta 30 minutos y ofrece personalización mediante system prompts, lo que facilita ajustar el estilo o el comportamiento de las respuestas.
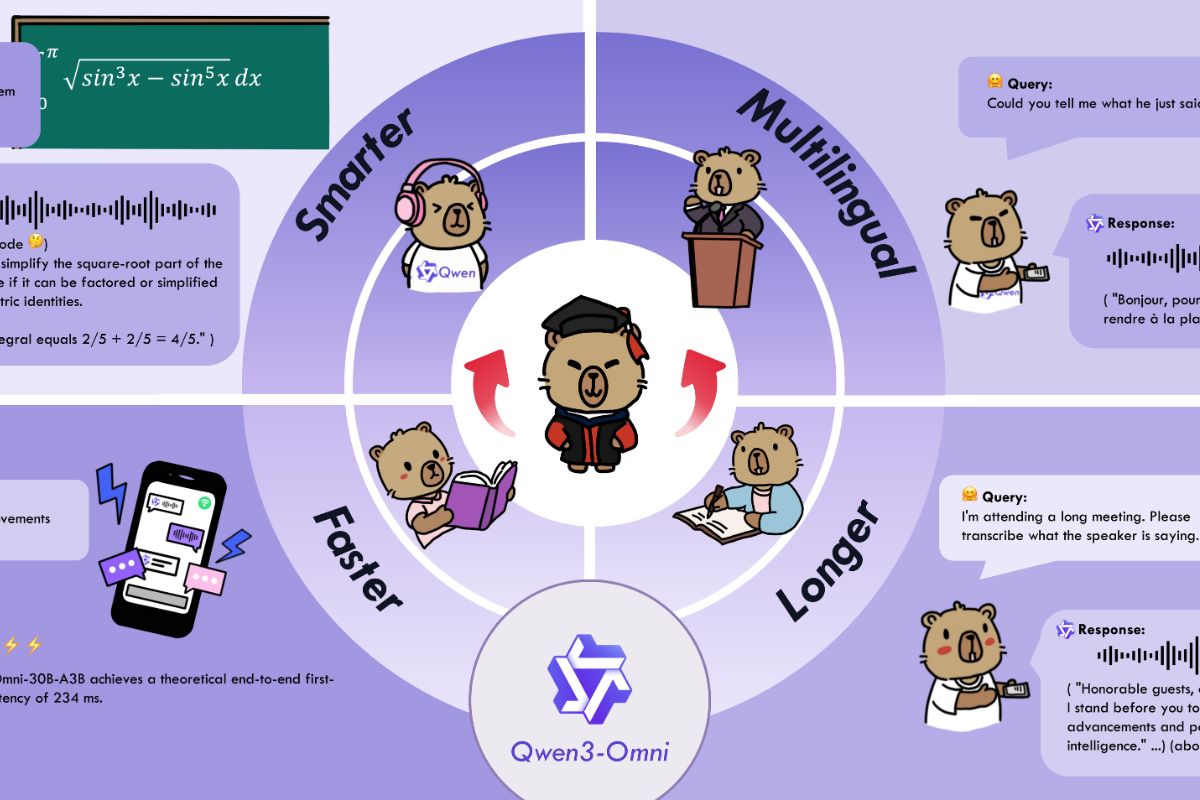
En cuanto al rendimiento, el modelo ha sido evaluado en 36 pruebas relacionadas con audio y audiovisual, logrando resultados de referencia en 32 de ellas. También destaca por su baja latencia, alcanzando 211 milisegundos en escenarios solo de audio y 507 milisegundos en audio-vídeo.
Otra de sus capacidades es la integración con herramientas externas mediante llamadas a funciones, lo que facilita su uso en aplicaciones que requieren interacción con servicios adicionales. Además, se incluye un modelo abierto de generación de subtítulos de audio, pensado para reducir errores y mejorar el detalle en transcripciones automáticas.
Finalmente, Qwen3-Omni se basa en una arquitectura denominada Thinker-Talker, que separa la generación de texto y la producción de voz en tiempo real. Este diseño, junto con el uso de un sistema Mixture of Experts y codificación multicódigo, busca optimizar la velocidad y la calidad en la interacción multimodal.
De cara al futuro, el equipo de desarrollo ha señalado que se trabaja en nuevas funciones, como reconocimiento de voz multihablante, OCR en vídeo y mejoras en el aprendizaje proactivo audiovisual, así como en la integración de flujos de trabajo basados en agentes.